Basics of Big Data – Part 2 - Hadoop
As discussed in Part 1 of this series, Hadoop is the foremost among tools being currently used for deriving value out of Big Data. The process of gaining insights from data through Business Intelligence and analytics essentially remains the same. However, with the huge variety, volume and velocity (the 3Vs of Big Data), it’s become necessary to re-think of the data management infrastructure. Hadoop, originally designed to be used with the MapReduce algorithm to solve parallel processing constraints in distributed architectures (e.g. web indexing) of web giants like Yahoo or Google, has become the de-facto standard for Big Data (large-scale data-intensive) analytics platforms.
What is Hadoop?
Think of Hadoop as an operating system for Big Data. It is essentially a flexible and available architecture for large scale computation and data processing on a network of commodity hardware.
Conceptually, the key components of the Java-based Hadoop framework are a file store and a distributed processing system:
1. Hadoop Distributed File System (HDFS): provides reliable (fault-tolerant), scalable, low-cost storage
2. MapReduce: Batch-oriented, distributed (parallel) data processing system with resource management and scheduling
As of October 2013, the 2.x GA release of Apache Hadoop also included an enhancement - a key third component:
3. YARN: a general purpose resource management system for Hadoop to allow MapReduce and other data processing services
Hadoop architecture stack
Open-source Hadoop is an Apache project. There are however commercial distributions of Hadoop (similar to UNIX distros) most notably from Cloudera, Hortonworks, MapR, IBM, Amazon etc. The Hadoop ecosystem has several projects in development, seeking to enhance the Hadoop framework to make it more suited to performing Big Data tasks including ETL and analytics.
The key components of the Hadoop distribution:
1. Distributed file system and storage - HDFS
HDFS - a Java based file system providing scalable and reliable data storage, designed to span large clusters of commodity servers
2. Data integration - Flume, Sqoop
Flume - service for integrating large amounts of streaming data (e.g. logs) into HDFS
Sqoop - tool for transferring bulk data between Hadoop and structured databases e.g. RDBMSes
3. Data access - HBase, Hive, Pig, Impala (CDH version for interactive SQL query), Storm, MapReduce jobs in Java/Python etc.
HBase - a non-relational (NoSQL) columnar database running on top of HDFS.
Hive - a data warehouse infrastructure built on Hadoop, providing a mechanism to project structure onto the data and query it using SQL like language - HiveQL
Pig - allows writing complex MapReduce jobs using a scripting language - PigLatin
Impala - SQL query engine running natively in Hadoop, allows querying data in HDFS and HBase. It is part of Cloudera’s CDH distribution.
Storm - provides real-time data processing capabilities to Hadoop which is traditionally batch oriented (based on MapReduce).
4. Operations- Oozie, Ambari, ZooKeeper
Oozie - Java web application used to schedule Hadoop jobs
Ambari - Framework and tools to provision, manage and monitor Hadoop clusters
ZooKeeper - provides operational services for Hadoop - e.g. distributed configuration service, named registry, synchronization service etc.
5. Resource management - YARN
YARN - separates the resource management and processing components in Hadoop 2.x which used to be done in MapReduce packages in Hadoop 1.x
A schematic of Cloudera’s Hadoop distribution (CDH) is shown below:
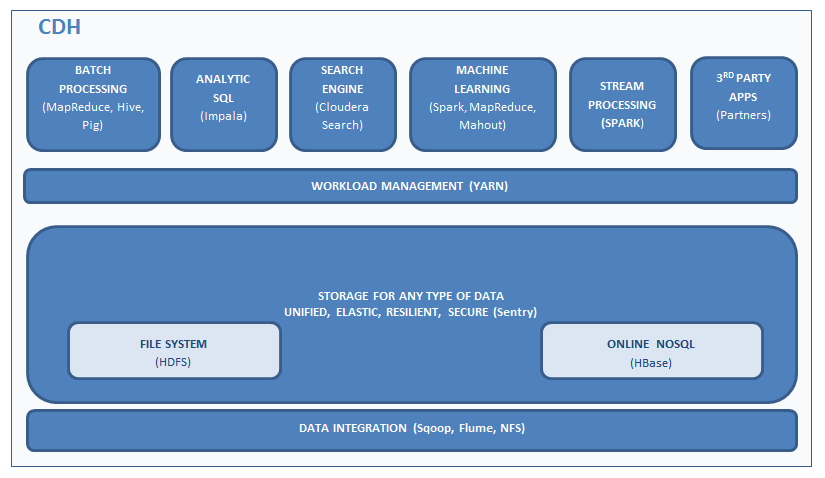
Why Hadoop?
Hadoop has gained immense traction in a very short amount of time and is proving useful in a range of applications, including deriving insights from Big Data analytics.
The key advantages of Hadoop as a data processing platform are:
-
Scalability and availability - Due to its ability to store and distribute extremely large datasets across hundreds of inexpensive servers operating in parallel, Hadoop offers extreme scalability. With high-availability HDFS feature in Hadoop 2.0 providing redundant namenodes for standby and failover, Hadoop now also provides high availability
-
Cost-effectiveness - Due to its design incorporating fault-tolerance and scale-out architecture, Hadoop clusters can be built with relatively inexpensive commodity hardware instead of costly blade servers, thereby providing great savings for storage and computing abilities on a per TB basis.
-
Resilience - With built-in fault tolerance, e.g. multiple copies of data replicated on cluster nodes, and with high availability HDFS in version 2.0, Hadoop provides cost-effective resilience to faults and data loss.
-
Flexibility and performance - Ability to access and store various types of data - both structured and unstructured, with no constraints of schema-on-write, along with the emergence of new ways of accessing and processing data - e.g. Storm for real-time/streaming data, SQL-like tools including Impala, Hadapt, Stinger etc.
Due to these key advantages, Hadoop lends itself to several data processing use cases. Key use cases are:
- Data store / Enterprise data warehouse (EDW) - cost-effective storage for all of an organization’s ever expanding data
- Active archive - allowing cost-effective querying on historical data from archival systems
- Transformation - executing data transformations (T step of ETL/ELT) for improved throughput and performance
- Exploration - allows fast exploration and quicker insights from new questions and use cases, taking advantage of Hadoop’s schema-on-read model instead of schema-on-write models of traditional relational databases
- Real-time applications - usage of flexible add-ons like Storm to provide dynamic data mashups
- Machine learning, data mining, predictive modeling and advanced statistics
The early adopters of Hadoop are the web giants like Facebook, Yahoo, Google, LinkedIn, Twitter etc.
Facebook uses Hadoop - Hive and HBase for data warehousing (over 300 PB in aggregate and over 600 TB daily data inflows) and real-time application, serving up dynamic pages customized for each of its over 1.2 billion users.
Yahoo uses Hadoop and Pig for data processing and analytics, web search, email antispam and ad serving with more than 100,000 CPUs in over 40,000 servers running Hadoop with 170 PB of storage .
Google had used MapReduce to create its web index from crawl data and also uses Hadoop clusters on its cloud platform with Google Compute Engine (GCE).
LinkedIn uses Hadoop for data storage and analytics driving personalized recommendations like “People you may know” and ad targeting.
Twitter uses Hadoop - Pig and HBase for data visualization, social graph analysis and machine learning.
Limitations of Hadoop
While Hadoop is the most well-known Big Data solution, it is just one of the components in the Big Data landscape. While in theory, Hadoop is infinitely scalable and resilient and allows a great deal of flexibility in storing structured and unstructured data, in practice, there are several considerations to be taken care of while architecting Hadoop clusters due to the inherent limitations of Hadoop.
1. Workloads- Hadoop is suitable for various types of workloads, however mixed workloads or situations where the workload may vary widely or is not known ahead, makes it difficult to optimize the Hadoop architecture.
2. Integration - Hadoop should not be a stand-alone solution, else it will quickly become a data silo unconnected with the rest of the data management infrastructure. The Hadoop strategy needs to fit into the overall data management and processing framework of the organization to allow for growth and maintenance while not sacrificing on flexibility and agility
3. Security- In the enterprise, security is a big deal. While Hadoop was originally built without a security model, the Hadoop ecosystem is evolving with various projects for security, including Kerberos authentication, the Sentry offering from Cloudera, Project Rhino from Intel, Apache Knox as reverse proxy (with contribution from Hortonworks) or using Apache Accumulo for cell-level security; however most are complex to setup and there is still no reference standard across deployments.
4. Complexity- the complexity of Hadoop as a Big Data platform lies in its evolving ecosystem of newer technologies, with most data warehousing and analytics specialists skilled in traditional relational databases, SQL and techniques which are difficult to use on Hadoop due to the lack of tools (e.g. still evolving SQL access) and the need for additional skills including data mining or advanced statistical techniques.
5. Availability- Up until the 2.0 release, Hadoop with single-master nodes in HDFS and MapReduce was subject to single point of failure.
6. Inefficiency- HDFS is inefficient for handling small files thereby making analysis on smaller datasets extremely inefficient. This is especially painful while designing models or finding patterns on smaller datasets. MapReduce is also a batch-oriented architecture not suitable for real-time access, but this is being addressed with tools like Storm. Tools like Impala provide interactive SQL-like querying on HDFS, which helps in improving quick adhoc analysis on smaller datasets.
7. Processing framework - Not all data processing problems or analytic questions can be designed with the MapReduce framework. Hadoop is therefore ill suited for such problems which cannot be expressed as problems with Map and Reduce steps and need other data processing paradigms. There are improvements being developed with Storm for real-time access or Spark for improving the data analytics performance with in-memory distributed computing to get around these issues.
In the next parts of this series, I will explore topics of building a Hadoop data warehouse, big data analytics with tools like R as well as other Big Data solutions, Hadoop enhancements and alternatives to Hadoop.
Read the series on Big Data: Part-1 : Basics, Part-2 : Hadoop, Part-3 : Hadoop data warehouse and Part-4 : NoSQL
comments powered by Disqus