Big Data Basics - Part 4 : NoSQL and NewSQL explained
This is the fourth part of a series of posts on big data. Read the previous posts here: Part-1, Part-2 and Part-3.
With the ongoing data explosion, and the improvement in technologies able to deal with it, businesses are turning to leverage this big data for mining insights to gain competitive advantage, reinvent business models and create new markets.
A huge amount of this “big data” volumes comes from system logs, user generated content on social media like Twitter or Facebook, sensor data and the like. All of these types of data are what we call “unstructured”. Businesses which do not leverage the vast amount of unstructured data available to them, risk losing out valuable insights from such data types.
Traditional data storage systems - primarily relational databases are not designed from the ground up to handle unstructured data. While you can store unstructured data as objects (blob, text, images etc.) in several leading databases, these do not lend themselves to fast and easy retrieval of information or mining of information e.g. by using structured query language (SQL). What is required in such cases, are a new type of databases, which are flexible enough to manage such new data types, not only for storage but also for retrieval of information. Responding to such demand, the past few years have seen the proliferation of a new class of databases which are capable of handling both structured and unstructured data and are not constrained by schema requirements of SQL.
It is this class of databases which are referred to as NoSQL or NewSQL, with the retronym “Not-only SQL”.
NewSQL are similar to NoSQL, except that they support ACID (Atomicity, Consistency, Isolation, Durability) properties similar to relational databases, which may not be supported uniformly by all NoSQL databases. Some examples of NoSQL systems are: HBase, MongoDB, Cassandra, Couchbase and Riak. Some NewSQL systems are: VoltDB, NuoDB and SAP HANA.
NoSQL : Term coined in 1998 by Carlo Strozzi for his relational database without SQL interface.
The shift from relational databases - why NoSQL and NewSQL?
What is the motivation behind these new database systems - NoSQL and NewSQL? Why do we need to even consider shifting away from relational database systems? After all, RDBMSes have a proven track record in being able to be used for a variety of applications, supporting concurrent users and transactions as well as analytic workloads on data marts and data warehouses.
Well, there’s nothing wrong per se with relational database systems. However, like any other system, they have their limits of usefulness and performance and there may be different systems which are better for certain use cases or workloads. Note the following limitations of RDBMSes:
-
Most relational databases use a table-row-column storage with normalization for transactional systems (remember the star-schema or denormalization designs of data marts and data warehouses were workarounds for the query retrieval performance issues with multi-joins in relational DB implementations).
-
CRUD (Create, Read, Update, Delete) operations in transactional relational systems lead to loss of version history (similar to SCD-slowly changing dimension- modeling for data warehouses), which may not be desired in a big-data age, due to plummeting storage costs.
-
SMP (symmetric multi-processing) shared-everything architectures of relational systems don’t scale out, rather scale-up (vertically).
Over the past decade, we’ve seen the rise in rich interactive web applications (think Google, Facebook, Twitter, Amazon etc.) with massive scale in terms of the number of concurrent users, the data collected and processed and the amount of semi-structured or unstructured data managed.
In the data warehousing space as well, as more and more data started getting collected, organizations started to hit the limits of the traditional SMP (symmetric multi-processing) database architecture.
“Sharding” a database, or partitioning it across several server instances is possible with SQL systems, but is complex. Led by Google, Facebook, LinkedIn and Amazon, there started a search for alternative technologies and systems which could scale rapidly for massively interactive internet applications, as well as shift to an MPP (massively parallel-processing) paradigm for data warehousing.
This led to open source NoSQL projects which were soon followed by commercial companies invested in NoSQL technology. NoSQL databases usually support “auto-sharding”, i.e. they natively and automatically spread data across several distributed servers.
Initial NoSQL systems sacrificed ACID+ concepts as a trade-off for scalability. Several key-value NoSQL databases used the “eventual-consistency” BASE° model to achieve high-availability. However with advances in technology like in-memory and increasing adoption of shared-nothing architectures, these systems have improved greatly to support ACID concepts, and now offer SQL as one of their main interfaces. These are now being called as NewSQL systems.
+ACID concepts - key pillars of relational databases and a must for transactions.
A- Atomicity, C - Consistency, I- Isolation, D- Durability
°BASE : Basically Available, Soft-state, Eventual consistency
NoSQL data models
With a relational database system, you must define a schema before you can load data into your database. Any record added needs to adhere strictly to this schema with fixed columns and data types. Changing schemas has proved to be difficult with most commercially available relational database systems (mostly through implementation though), and this is especially a problem when dealing with a partitioned database spread across many machines (sharding). Projects where requirements are fast evolving, need an agile iterative approach, and the rigid schemas of relational systems become a bottleneck in such cases.
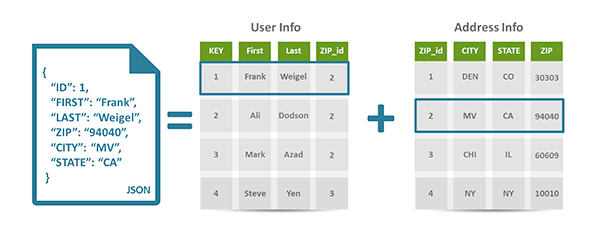
NoSQL databases have different data models and allow insertion of data without a predefined schema, thereby making it easier to manage evolving data capture and management needs, as well as rapid iterative approaches. The data models used by most NoSQL databases can be categorized as:
-
Key-value store - one of the simplest and most efficient models. Every item in the database is stored as an attribute (key) with its value. Inefficiencies arise in cases where part of the value needs to be queried or updated. Examples: Riak, Voldemort, Amazon SimpleDB.
-
Column-family database / wide-column stores - similar to key-value stores, except the keys point to multiple columns instead of rows, arranged by column family. Examples: Cassandra, HBase
-
Document store - pair each key with a complex data structure (usually in JSON or XML format) known as a document. These are essentially nested key-value stores, with keys being associated with nested values. Documents may contain key-value pairs, key-array pairs or even nested documents. Examples: MongoDB, CouchDB
-
Graph database - these use a flexible graph model to store information about networks, useful for social connections. Examples: Neo4J, InfoGrid
The key reasons for the trend to move away from relational systems to the NoSQL and NewSQL systems are therefore:
- Ability to scale dynamically to support more users and data
- Improved performance for highly responsive internet applications
- Flexible data models to allow storage and query of semi-structured and unstructured data
The best of both worlds - NewSQL
Most NoSQL systems initially did not offer any SQL interfaces, rather object-oriented APIs. However, most new systems now are increasingly supporting ACID concepts and hence transactions, as well as provide SQL interfaces. The recent proliferation of SQL-on-Hadoop product offerings in the big-data space is a case in point. These new systems with transaction support and SQL interfaces are labeled NewSQL++ systems.
++NewSQL - term coined by 451 Group analyst Matthew Aslett in a 2011 research paper
While NoSQL systems have been recognized to be better than relational databases for scalability and performance, and have simplified automated sharding of databases, there appear to be higher costs and significant development and refactoring efforts are required for NoSQL systems when compared to SQL systems. Moreover in a NewSQL system - transaction support (consistency) and usability of SQL systems can be combined with the high availability and scalability of NoSQL systems. This provides the best of both worlds. One of the significant NewSQL systems is F1 - a system built by Google to support it’s ad business - Adwords, and described in the whitepaper titled F1: A Distributed SQL Database that scales.
There are no uniform architectures of NewSQL systems, but common features are:
- Support for relational data model (tables-rows-columns). Most support additional NoSQL models like JSON documents.
- Provide SQL as a primary interface to these systems
- Transaction support (Consistency in ACID)
Several NewSQL systems use in-memory technology and have been designed from the ground-up with a distributed architecture. Some use a middleware layer to provide automated sharding. The strong consistency comes at the cost of higher latency for writes, which is offset by in-memory technology as well as use of newer storage options like solid-state devices (SSD/Flash storage). NewSQL systems promise to provide the scalability, availability, transparent sharding, and cost benefits of NoSQL systems with the usability, familiarity, and transactional guarantees expected from RDBMSes.
Finally - a tongue-in-cheek look at the NoSQL boom from Geek&Poke 😄

Read the series on Big Data: Part-1 : Basics, Part-2 : Hadoop, Part-3 : Hadoop data warehouse and Part-4 : NoSQL
comments powered by Disqus