The data science project lifecycle
How does the typical data science project life-cycle look like?
This post looks at practical aspects of implementing data science projects. It also assumes a certain level of maturity in big data (more on big data maturity models in the next post) and data science management within the organization. Therefore the life cycle presented here differs, sometimes significantly from purist definitions of ‘science’ which emphasize the hypothesis-testing approach. In practice, the typical data science project life-cycle resembles more of an engineering view imposed due to constraints of resources (budget, data and skills availability) and time-to-market considerations.
The CRISP-DM model (CRoss Industry Standard Process for Data Mining) has traditionally defined six steps in the data mining life-cycle. Data science is similar to data mining in several aspects, hence there’s some similarity with these steps.
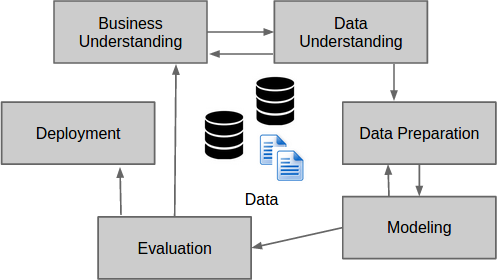
The CRISP model steps are:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation and
- Deployment
Given a certain level of maturity in big data and data science expertise within the organization, it is reasonable to assume availability of a library of assets related to data science implementations. Key among these are:
- Library of business use-cases for big data/ data science applications
- Data requirements - business use case mapping matrix
- Minimum data quality requirements (test cases to ensure minimum level of data quality to ensure feasibility)
In most organizations, data science is a fledgling discipline, hence data scientists (except those from actuarial background) are likely to have limited business domain expertise - therefore they need to be paired with business people and those with expertise in understanding the data. This helps data scientists gain or work together on steps 1 and 2 of the CRISM-DM model - i.e. business understanding and data understanding.
The typical data science project then becomes an engineering exercise in terms of a defined framework of steps or phases and exit criteria, which allow making informed decisions on whether to continue projects based on pre-defined criteria, to optimize resource utilization and maximize benefits from the data science project. This also prevents the project from degrading into money-pits due to pursuing nonviable hypotheses and ideas.
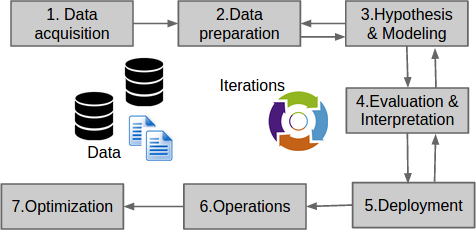
The data science life-cycle thus looks somewhat like:
- Data acquisition
- Data preparation
- Hypothesis and modeling
- Evaluation and Interpretation
- Deployment
- Operations
- Optimization
Data Acquisition - may involve acquiring data from both internal and external sources, including social media or web scraping. In a steady state, data extraction and transfer routines would be in place, and new sources, once identified would be acquired following the established processes.
Data preparation - Usually referred to as “data wrangling”, this step involves cleaning the data and reshaping it into a readily usable form for performing data science. This is similar to the traditional ETL steps in data warehousing in certain aspects, but involves more exploratory analysis and is primarily aimed at extracting features in usable formats.
Hypothesis and modeling are the traditional data mining steps - however in a data science project, these are not limited to statistical samples. Indeed the idea is to apply machine learning techniques to all data. A key sub-step is performed here for model selection. This involves the separation of a training set for training the candidate machine-learning models, and validation sets and test sets for comparing model performances and selecting the best performing model, gauging model accuracy and preventing over-fitting.
Steps 2 through 4 are repeated a number of times as needed; as the understanding of data and business becomes clearer and results from initial models and hypotheses are evaluated, further tweaks are performed. These may sometimes include Step 5 (deployment) and be performed in a pre-production or “limited” / “pilot” environment before the actual full-scale “production” deployment, or could include fast-tweaks after deployment, based on the continuous deployment model.
Once the model has been deployed in production, it is time for regular maintenance and operations. This operations phase could also follow a target DevOps model which gels well with the continuous deployment model, given the rapid time-to-market requirements in big data projects. Ideally, the deployment includes performance tests to measure model performance, and can trigger alerts when the model performance degrades beyond a certain acceptable threshold.
The optimization phase is the final step in the data science project life-cycle. This could be triggered by failing performance, or due to the need to add new data sources and retraining the model, or even to deploy improved versions of the model based on better algorithms.
Agile development processes, especially continuous delivery lends itself well to the data science project life-cycle. As mentioned before, with increasing maturity and well-defined project goals, pre-defined performance criteria can help evaluate feasibility of the data science project early enough in the life-cycle. This early comparison helps the data science team to change approaches, refine hypothesis and even discard the project if the business case is nonviable or the benefits from the predictive models are not worth the effort to build it.
comments powered by Disqus