A gentle introduction to Machine Learning
Machine Learning is a big part of big data and data science. A subset of artificial intelligence - a branch of science notorious for requiring advanced knowledge of mathematics. In practice though, most data scientists don’t try to build a Chappie and there are simpler, practical ways to get started with machine learning.
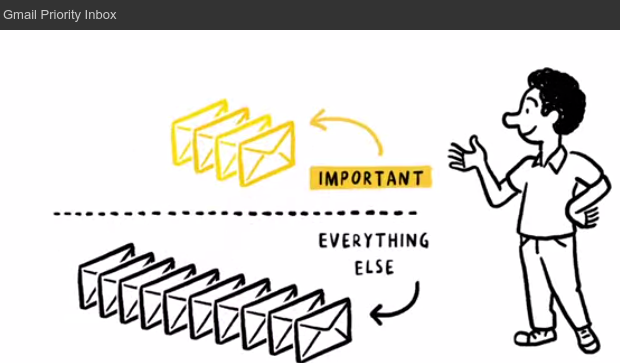
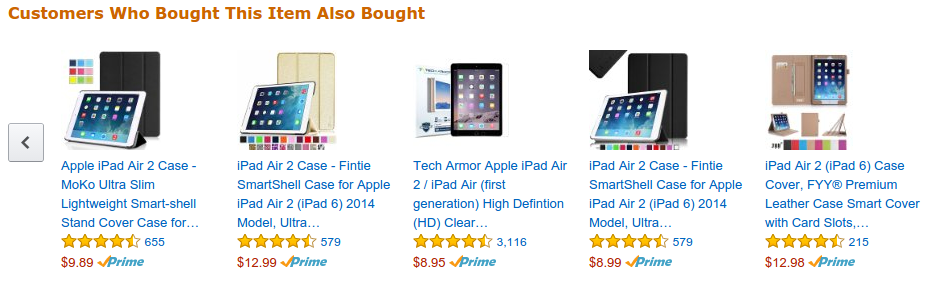
Machine learning in practice involves predictions based on data. Notable examples include Amazon’s product recommendations with the “customers also bought” scroll-list, or Gmail’s priority inbox or any email spam-filter feature. How do these work? For Amazon, clicks by the user is used to learn and predict user behavior and propensity (likelihood) to buy certain items. The items the user is most likely to buy are then displayed on the recommendation system. Gmail’s system learns from the messages which the user reads and/replies to and prioritizes them.
In both cases, there are some predictions made based on certain example usage of the data. Thus in essence, machine learning is about predictions based on models, which themselves are created based on examples.
More specifically, a machine learning model is a set of explanations of the relationships between the input data and the output predictions. These relationships are discovered from examples of input-output pairs. In machine learning terminology, the input data is also called features and the predictions are called output. Once a model has been created, it can be used on new inputs to predict outputs.
Machine learning models therefore “learn” to predict from examples. This learning is also known as “training” the model, and the associated good quality data-set is called “**training **data-set”. The stage where the model is used on new inputs is known as “testing” the model, and the data-set associated with it is called “test data-set”. There are different ways to perform this learning, with different types of algorithms to build models and perform predictions. Most common among these are Classification and Regression techniques. The Gmail spam-filter is an example of Classification technique. Given a set of emails marked as spam or not-spam, it learns the characteristics of emails and is then able to process future email messages to mark them as spam or not. Classification deals with prediction of which class ordinal data fits in, while regression deals with prediction of continuous numeric data. Example of regression is a best-fit line drawn through some data points for generalization. Both classification and regression are examples of supervised learning, as the algorithm is told to predict a label or target value.
The opposite of this is unsupervised learning - where there’s no label or target value given for the data. An example of this could be clustering - a task of grouping a items so that objects in the same group or cluster are more similar (in some sense or another) to each other than to those in other groups (clusters).
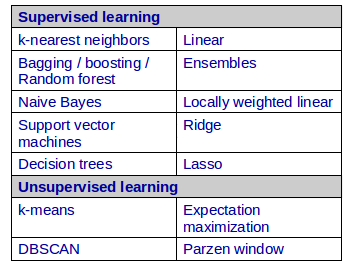
With so many choices, how do you choose the right algorithm? Without considering nuances of the data, a rule of thumb is to look at the objective of the prediction:
- If the prediction is to forecast a target value, we use supervised learning, else use unsupervised learning or density estimation algorithms.
It is important to note though, that this is not unbreakable, rather usage of algorithms is rather fuzzy. This is quite common in machine learning, where most problems are not deterministic in nature, and often a bunch of different algorithms are tried out to see how they perform. There are also ensemble models like Gradient Boosting - a regression technique which uses an ensemble of weak prediction models, typically decision trees to get an improved prediction model. An interesting tool based on symbolic regression, which infers the model from the data is Nutonian Eureqa, also dubbed as the robotic data scientist.
Many algorithms are different, but the steps to use one are similar:
Collect data > Prepare data > Analyze input data > Clean data/verify data quality > Train the algorithm > Test the algorithm > Iterate/Deploy. (See also my earlier post on the data science project lifecycle)
As with many other aspects (data wrangling) of data science, both R and Python are very popular languages for using machine learning techniques. There are also start-ups like BigML providing MLaaS or Machine Learning as a Service.
In conclusion of this post, a few points to remember: garbage in - garbage out:- data quality matters as much if not more than algorithms, quantity of data or complexity of algorithm are not substitutes for quality, and of course as with all predictions, machine learning can be wrong as well.
comments powered by Disqus