Why Spark is the big data platform of the future
Apache Spark has created a lot of buzz recently. In fact, beyond the buzz, Apache Spark has seen phenomenal adoption and has been marked out as the successor to Hadoop MapReduce.

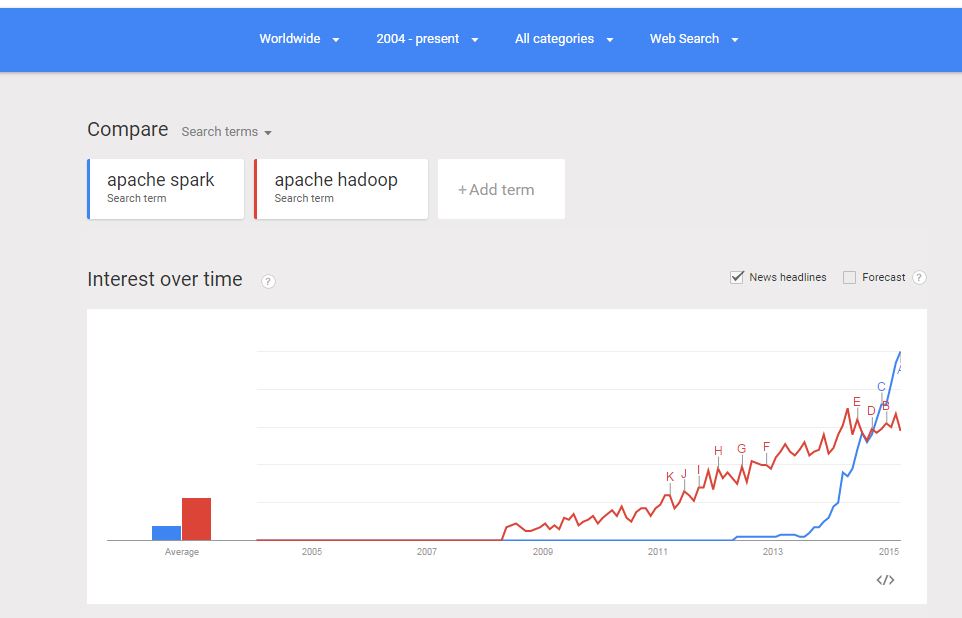
Google Trends confirms the hockey stick like growth in interest in Apache Spark. All leading Hadoop vendors, including Cloudera, now include Apache Spark in their Hadoop distribution.
So what exactly is Spark, and why has it generated such enthusiasm? Apache Spark is an open-source big data processing framework designed for speed and ease of use. Spark is well-known for its in-memory performance, but that has also given rise to misconceptions about its on-disk abilities. Spark is in fact a general execution engine - which has a greatly improved performance both in-memory as well as on-disk, when compared with older frameworks like MapReduce. With its advanced DAG (directed acyclic graph) execution engine, Spark can run programs up to 100x faster than MapReduce in memory, or 10x faster on-disk.
Why is Spark faster than MapReduce?
- A key step during MapReduce operations is the synchronization or “shuffle” step, intermediate between the “map”-step and the “reduce”-step. Apache Spark implements a sort-based shuffle design, which improves performance.
- Apache Spark also includes a DAG (directed-acyclic graph) which allow developers to execute DAGs all at once, not step by step. This eliminates the costly synchronization required by MapReduce. Note that DAGs are also used by Storm and Tez
- Spark supports in-memory data sharing across DAGs, so different jobs can work with the same data at a very high speed.
It’s important to remember that Hadoop is a decade-old technology, developed at a time when memory was still relatively expensive, and therefore took the design approach of persistence to disk as a way of maintaining state between execution steps. On the other hand, Spark was developed at UC Berkeley AMPLab in 2009 and then it was open-sourced in 2010 - when memory had become much cheaper. Therefore, Spark stores data in memory and transparently persists it to disk if needed, thereby achieving better performance. The core concept of Spark is this programming abstraction over data storage - called RDDs (Resilient Distributed Dataset).
Under the hood, Spark automatically distributes the data contained in RDDs across the cluster and parallelizes the operations performed on them.

The end result is that, on an average - the lines of code required to develop a distributed data processing program is much less in Spark, when compared with MapReduce. See more details on why Spark is the fastest open-source engine for sorting a petabyte. Clearly, faster execution has been one of the key reasons for the uptake of Spark, but Spark also provides further advantages. Similar to YARN, the upgrade of the Hadoop framework over the MapReduce-only version, Spark allows a wide range of workloads from batch to interactive and streaming. It reduces the burden of maintaining separate tools as in Hadoop - and provides APIs in Scala, Java, Python and SQL. Spark can run over a variety of cluster-managers, including Hadoop YARN, Apache Mesos, and Spark’s own standalone scheduler.
Spark components
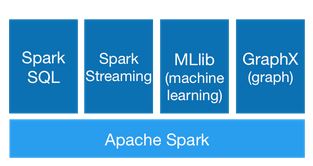
Spark Core - provides basic functionality of Apache Spark, including RDDs and APIs to manipulate them.
Spark SQL - A new component which replaces the older Shark (SQL on Spark) project, this package provides better integration with Spark Core, it allows querying data through SQL and HiveQL and supports many data sources from Hive tables, Parquet and JSON. Spark SQL also allows developers to intermix SQL queries with the code for data manipulations with RDDs in Python, Java, and Scala. It also provides fast SQL connectivity to BI tools like Tableau or QlikView.

Spark Streaming - based on micro-batching, this component enables processing of real-time streaming data. It uses DStreams, which are series of RDDs, to process real-time data. The Spark Streaming API is very similar to the Spark Core RDD APIs, making it easy for developers to reuse and adapt code for batch to interactive or real-time applications.
MLlib - provides a library of machine learning algorithms including classification, regression, clustering, and collaborative filtering, as well as model evaluation and data import.
GraphX - provides an API for graphs and graph-parallel computations and operators for manipulating graphs and a library of graph algorithms.
The SparkR project aims to provide a light-weight front-end to use Apache Spark from R. Work is on to integrate SparkR into Spark.
Recently, Spark has introduced a dataframe library with R/Pandas syntax for use across all of the Spark language APIs and an ML pipeline API which also integrates with data frames. Spark adoption is increasing manifold, boosted by increased third-part vendor support.
Databricks - the company spun out of AMPLab by the creators of Apache Spark, now provides Spark as a service on the cloud - with its own Databricks Cloud - which is in private beta. The Databricks cloud is designed to support data science in the lab as well as in the factory - by creating polyglot notebooks (mix of Scala/Java/Python/SQL possible) and building production pipelines for ETL and analytics jobs. Tableau and MemSQL have provided Spark connectors, Altiscale now provides Spark in the cloud and machine learning vendors like Nube are building products like Reifier to perform entity resolution and de-duplication using Spark. ClearStory Data provides Spark-based data processing and analytics. There is also a fledgling community of packages for Apache Spark.
Big data and data science projects are complex with an increasing diverse toolset which require massive integration efforts. Greater flexibility than that provided by MapReduce, capability to support a variety of workloads and a simpler, more unified ecosystem of tools which work out of the box on a general execution engine (Apache Spark) thus provide better simplicity than the complex zoo of Hadoop MapReduce projects. Together with SparkSQL and dataframes library, Spark democratizes access to distributed data processing beyond MapReduce programmers extending it to other developers and business analysts. Over and above, considering the fast performance of Spark, it is no wonder that Apache Spark continues to gain traction and looks all set to be the default framework for Big data processing in the near future. More info:
Read the series on Big Data: Part-1 : Basics, Part-2 : Hadoop, Part-3 : Hadoop data warehouse and Part-4 : NoSQL
comments powered by Disqus