Kafka - building real-time stream data pipelines
Over the past few years, Kafka has become the most exciting new addition in the big data distributed architecture. Originally developed at LinkedIn, its founders Jay Kreps, Jun Rao and Neha Narkhede have launched a company Confluent to develop its open-core business model. The software at its core, Apache Kafka reinvents the database log to provide a highly scalable and fault tolerant, high performance distributed system, which serves as the data pipeline backbone for stream data processing.
The motivation of its founders to build Kafka came from the lack of a modern architecture to handle the continuous flow with data. Traditional databases were for storage and ETL couldn’t manage data in real-time. With businesses undergoing digital transformations, more and more of the core business data is generated in real-time, which requires processing and analysis in real-time as well.
Kafka may look similar to traditional message queue systems, but unlike older MQ systems, it has built-in partitioning, fault-tolerance, better throughput and is massively scalable. Let’s look at how Kafka is built.
Core architecture:
- message - the unit of data in Kafka (similar to a row in an RDBMS). It’s basically an array of bytes, and can also have optional metadata in a key. A batch is a collection of messages. For efficiency, messages are written into Kafka in typically compressed batches.
- schema - this provides a structure so that the message content can be understood. Avro is most commonly used due to its compact serialization format, strong data typing and support for schema evolution, but other formats like JSON and XML can also be used.
-
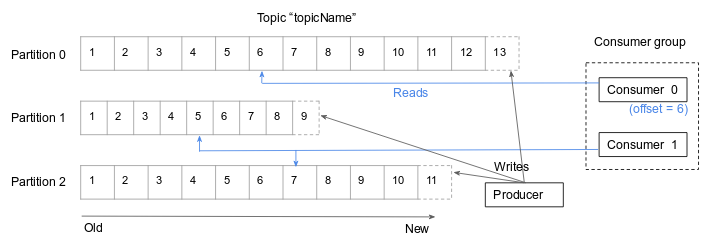
topics and partitions - In Kafka, messages are categorized into topics, which are in turn broken down into a number of partitions. A partition can be thought of as analogous to a database commit log, and a topic similar to a database table. Messages are written to a topic in append-only mode and read in order beginning to end. Each partition can be hosted on a different server, which allows Kafka to be horizontally scalable.
-
producers and consumers - these are Kafka clients or users of the publish/subscribe system. Messages are created by producers and read by consumers. The messages in the partitions are each assigned a unique identifier (sequential number) called the offset. The consumer keeps track of the offset to keep track of which messages it has already consumed.
-
brokers and clusters- are Kafka servers which receive messages from producers, assign offsets and store messages to disk as well as service consumers. Brokers are designed to operate as individual nodes as part of a cluster. One broker in the cluster, the cluster controller manages the administrative operations e.g. assigning partitions to brokers and monitoring for broker failures.
-
Zookeeper - Kafka uses Apache Zookeeper to store the metadata for the brokers or the cluster, as well as consumer client details. Consumers have the configurable choice to use either Zookeeper or Kafka for committing offsets, though the latter is preferred to remove dependency on Zookeeper.
Confluent drives the development of open-core additions to the Kafka ecosystem. The major additions are:
-
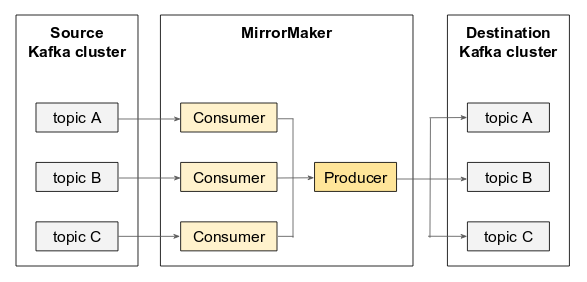
Cross cluster replication with MirrorMaker - this is a tool for mirroring data between two data centers. It uses a collection of consumers to consume selected topics (which are to be replicated) from the source cluster and send the messages to a target cluster using a producer.
-
Kafka Connect / with connectors (version 0.9 onwards) - a framework to move data between Kafka and other external systems e.g. databases, search indexes, file systems etc. As the Kafka connect architecture involves its own cluster, worker processes, connectors, source and sink tasks, I’ll review it in a later post.
Data pipelines
Kafka is now used as the some of the biggest data pipelines in the world (e.g. at LinkedIn, Uber or Netflix). Due to its architecture, it effectively decouples producers and consumers within the pipeline. Due to its durable retention of data in distributed partitions, Kafka also provides built-in fault-tolerance and scalability. As it is a streaming data platform, it can be used to support anything from near-real-time pipelines to hourly batches.
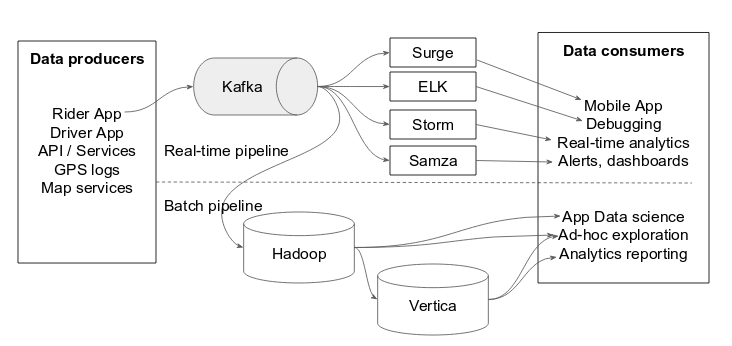
Fig. Kafka data pipeline at Uber
The continuous, low latency data processing allows Kafka to complement Hadoop and other big data processing systems. The continuous generation of core business data today is more suitable to continuous stream data processing. Common stream processing use cases are :
- Fraud and anomaly detection in real-time
- Real-time user targeting for advertising
- Customer profiling e.g. in insurance
- Operational monitoring of server and network infrastructure
The open-source community has continually added new features to Kafka. Confluent provides its open-source distribution with additional components including Kafka connect, Kafka streams and schema registry. However, improvements are still required in multi-tenancy and monitoring (admin UI like the Confluent control center) aspects.
comments powered by Disqus