9 features of modern data architectures
The last few years has seen a massive change in the data landscape. With the rise of big data, there’s been rapid innovation in the tools, skills and roles working on data systems. Data architectures have evolved beyond monolithic, centralized databases and unwieldy analytic applications to distributed, scalable architectures with simpler collaborative and interactive analytic tools. In this post, I look at the defining features of modern data architectures.
Modern data architectures generally feature the following (though not all of these may be present in the same system):
-
Scalable, distributed data systems - these are mostly NoSQL databases with scalable and distributed architecture. These are built for “fault-tolerance” from the ground-up like Hadoop, and also manage replication and distribution of data transparently.
-
Data lakes - the concept of data lake is a powerful and key element in modern data architectures. It allows the ingestion and storage of all data available at its most granular level, irrespective of whether it being structured or not.
-
Data pipelines - these go beyond the traditional ETL processes. Traditional ETL done with proprietary tools (including GUI based tools like Informatica) resulted in “black box” data usage. They also couldn’t often handle real-time data. Modern data pipelines are scalable, automated and use metadata-driven code for transformation of data in real-time, improving transparency and monitoring.
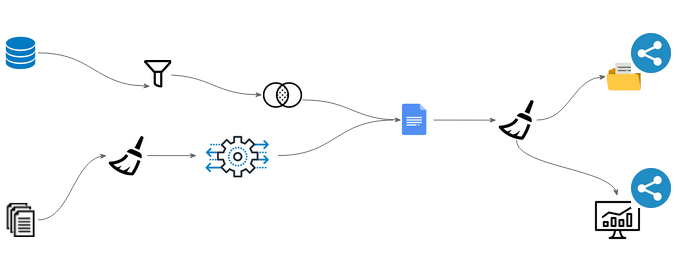
Fig. A data pipeline
-
Data science workspaces - modern data architectures provide easy to setup-and-use interactive workspaces (e.g. self-service clusters and/ data science notebooks) for data scientists and data engineers to work collaboratively while building data and AI solutions.
-
Search and discovery - the corollary to having data lakes is to have tools and processed for search and discovery of data. Some systems may use ElasticSearch-Logstash-Kibana (ELK) stack for search while others could even use AI-assisted search tools for assistance. Similarly business users need help in making sense of all this data with easy to use data discovery tools. These tools often provide data visualization and guided advance analytics.
-
Use of AI for data catalog and data quality - the volume of big data means that while manual processes may be sufficient for the establishing the initial catalog, these won’t suffice for managing problems of data quality or even cataloging of data on an ongoing basis. The task of extracting metadata, curating and validating it, resolving data quality issues needs to be automated with complementary human expertise solicited when required but without overwhelming.
-
Stream data platform - with digital transformation, corporations are moving to real-time continuous cycles of data processing for their core business. This real-time stream data requires refactoring of existing systems with modern solutions as traditional enterprise integration like ESBs are not usually very scalable as modern alternatives (e.g Kafka).
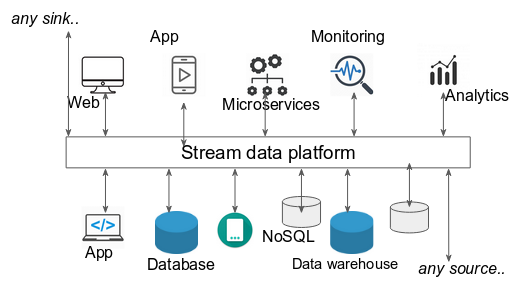
Fig. Stream data platform
-
SOA and API-based - at the base of modern data architectures is a services-oriented architecture. Use of well-defined interfaces and APIs allow loosely coupling components in the data pipelines improving overall reliability and scalability.
-
Data management and security - A modern data architecture is not just a data platform or a bunch of tools. It also includes modern processes to enable an agile, adaptive organization. Modern data management processes, with focus on security from the ground-up needs to be adopted. Data management in modern times is especially more challenging with often conflicting requirements of compliance regulation (privacy, GDPR etc.), interoperability and flexibility. New services like AI bring new complexities (ethics, explain-ability etc.) but also help in managing architectures more securely and with better performance.
Update: November 2017 - For further details refer to my talk on designing data lakes with open-source tools
Ref: *Intel drops its own Hadoop distribution
comments powered by Disqus